Project Overview
Introduction
The first half of 2017 was a time of significant transition for Enigma’s business. From the summer of 2016 to June 2017, Enigma completely redesigned, rebranded, and relaunched Public, one of its flagship data infrastructure products. I was tasked with redesigning the metadata editing feature of Enigma Public.
To comply with my non-disclosure agreement, I have omitted and changed confidential information in this project. The designs presented here may differ slightly from the original, and do not necessarily reflect the views of Enigma.
Project Introduction
My Role
I was one of three designers to work on Public alongside a team of several front and back-end engineers and our product manager. I was responsible for the delivery of Public’s metadata editor feature.
Project Introduction
Product Overview
Enigma was founded in 2011 with the goal of gathering and standardizing the world’s public data into one searchable, organized, and centralized place. Since its founding, Enigma has grown to have one of the largest repositories of public data in the United States, all of which is available under a creative-commons license for anyone to freely use.
Although “public data” is technically publically available, that doesn’t mean it’s easily accessible. Often, the desired datasets must be specifically requested through a Freedom of Information Act (FOIA) request, which can take weeks to process. After making the request, datasets often get mailed via physical CDs or DVDs, which further slows down the process. Even if datasets are downloadable through an agency’s website, they can come in various obscure formats and aren’t the easiest to find and digest.
One of the keys to Enigma’s value lies in ingesting all of this data and making it easier to comprehend. Apart from simply having it all in one place, a main way this is accomplished is through detailed and thorough metadata. Metadata usually takes the form of detailed dataset descriptions for fields and descriptions - a simple piece that is often lacking or unclear in the official data source.
Project Introduction
The Original Metadata Editor
Providing detailed metadata has been the dedicated job of someone on Enigma’s team since early in the company’s history. The original software that was used for was in need of a much overdue revamp as it had remained completely untouched since Enigma’s founding.
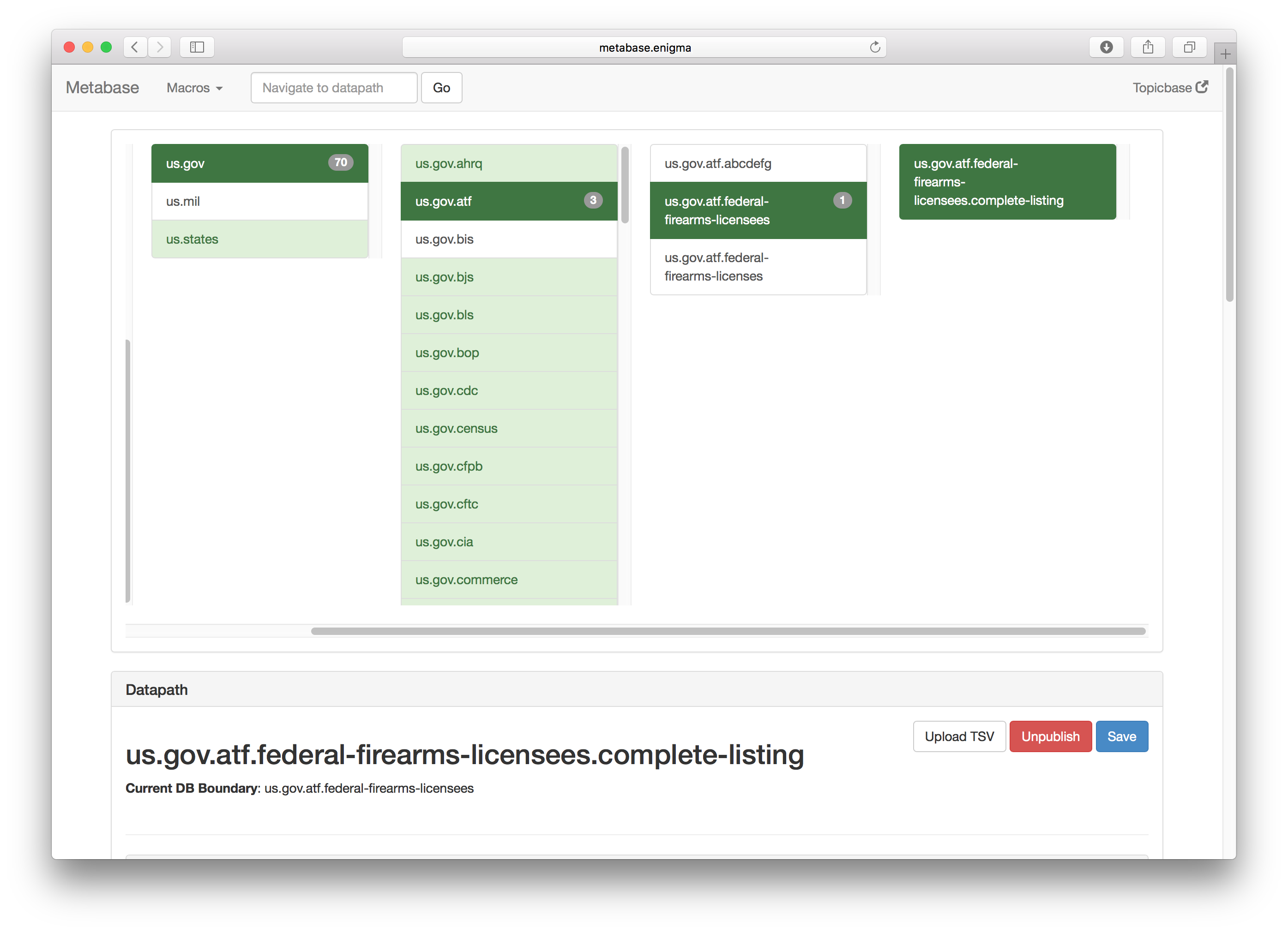
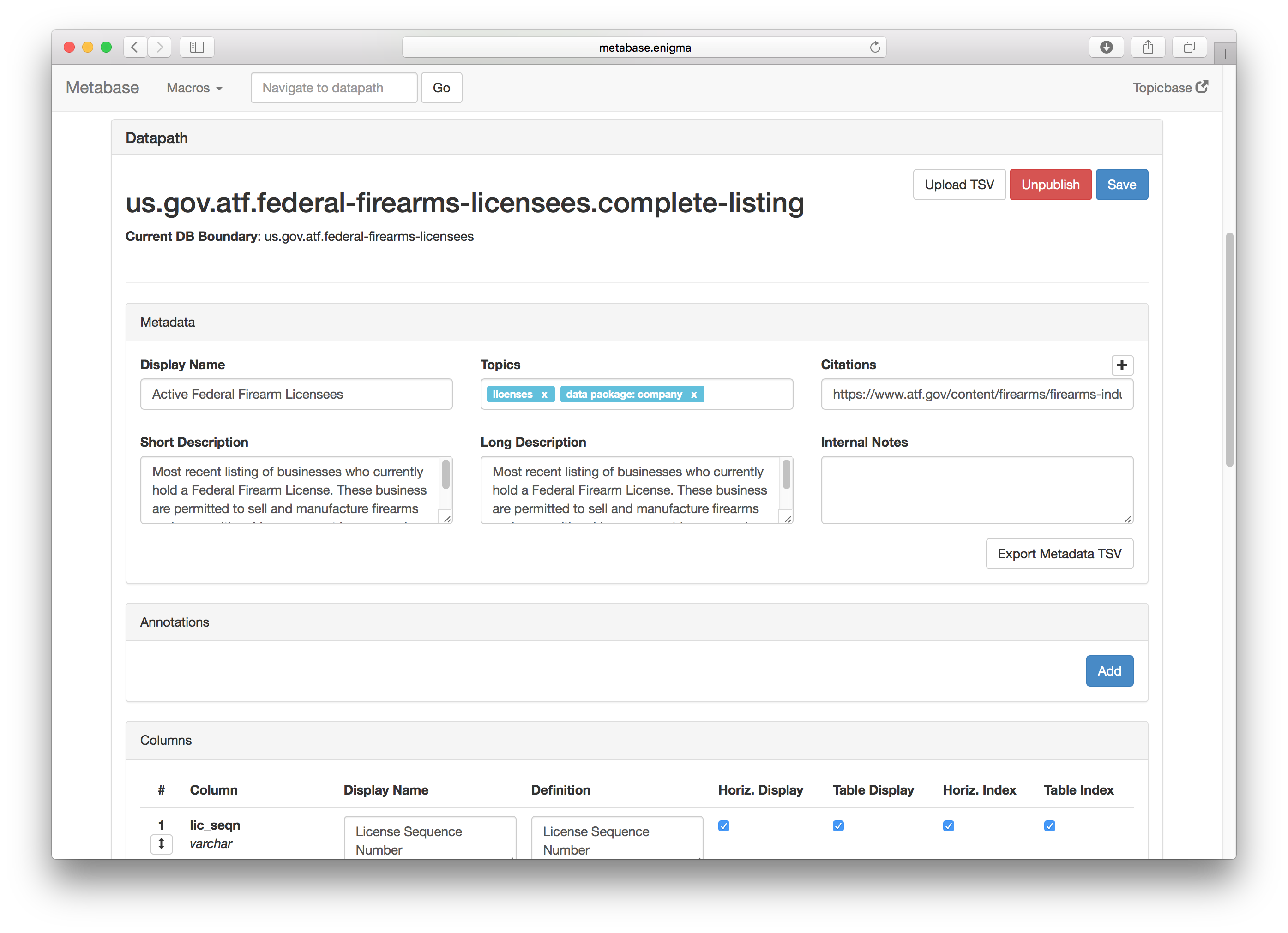
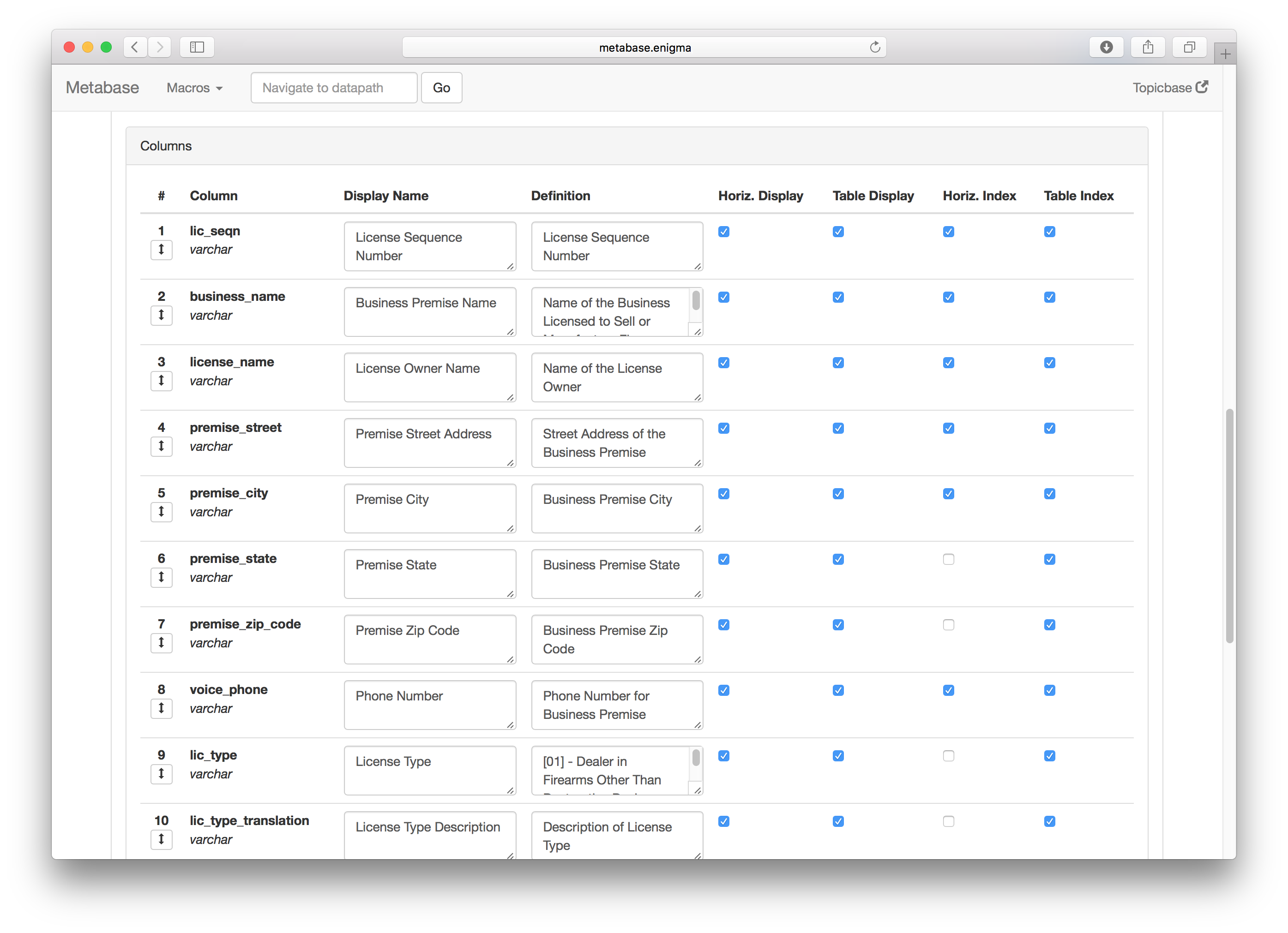
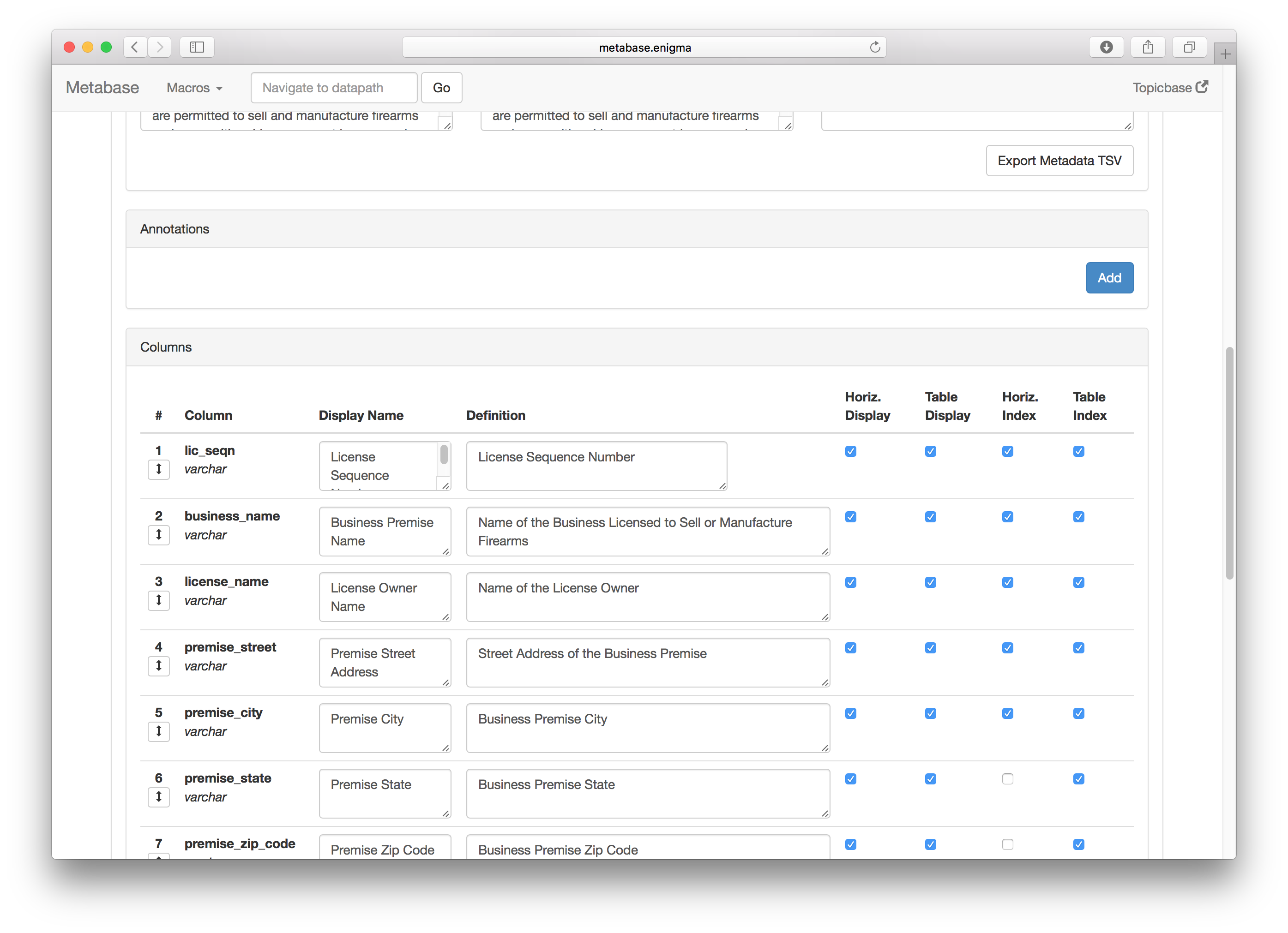
The old design had some major usability issues. Apart from a poor UI that overloaded the user with information, there were several major problems with the old design:
1. The lack of a good way of applying one set of metadata to multiple datasets. The problem was that when, for example, there are ten datasets with similar but not identical schemas, the metadata had to be copied manually to each one.
2. The inability to reorder more than one dataset column at a time.
3. The inability to get accurate versioning control of previous edits made by other users.
The Design
Redesigning the Metadata Manager
Although the redesigned metadata editor was intended to be used mainly by internal Enigma employees, we didn’t want to let that stop us from creating the best experience possible. After all, the fact that our users are required to use the software shouldn’t be an excuse to create a sub-par experience.
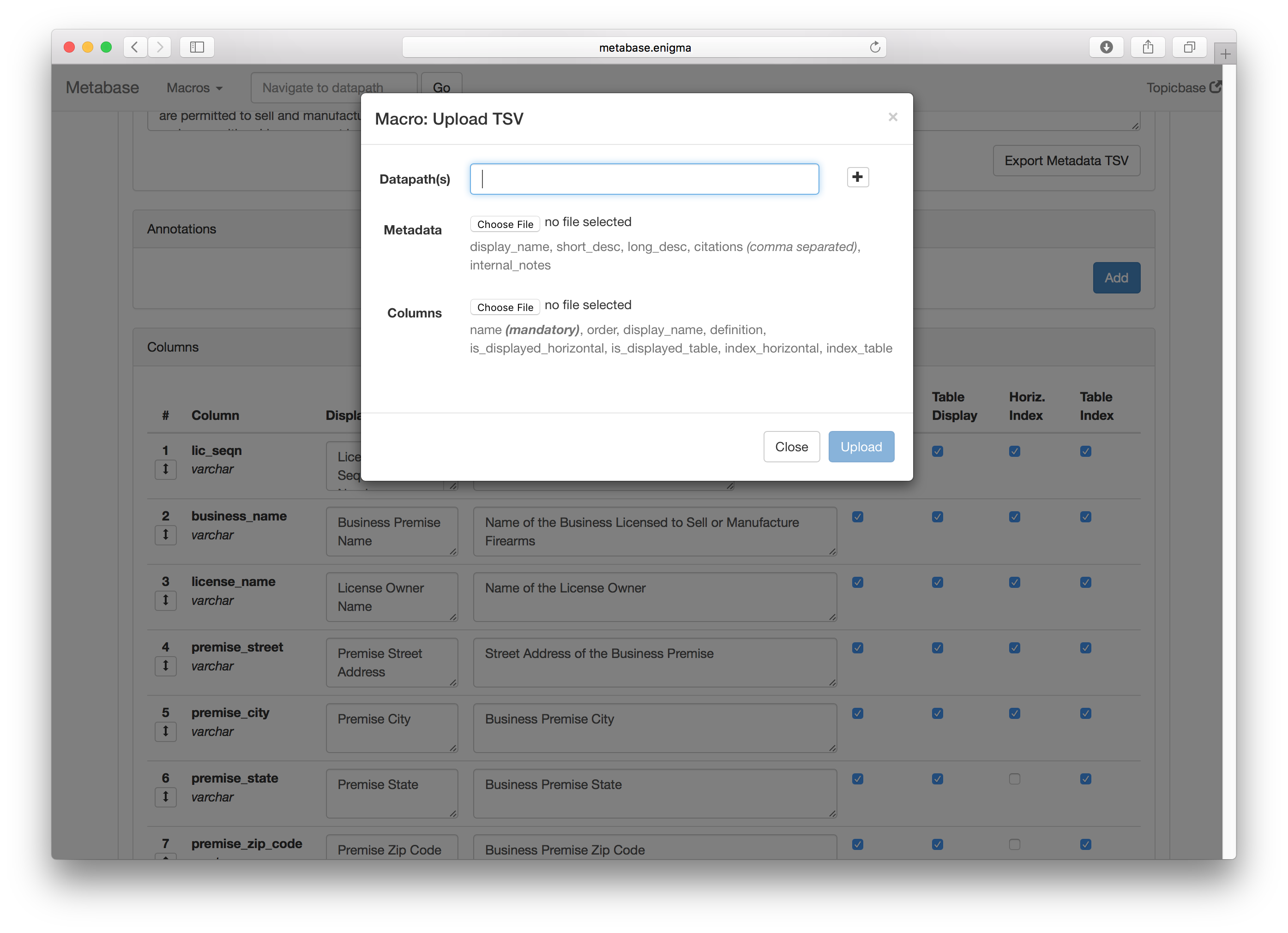
The Design
Key improvements
We knew that with limited development resources, it was going to be impossible to create the perfect tool. At the time the metadata editor was going into production, much of our team’s engineers were tied up with redesigning the rest of Enigma Public, and the externally-facing parts of the design understandably took development priority.
Knowing that not every issue could be addressed, we were forced to triage the implementation of features based on their importance. I built off of the internal user feedback that had been gathered before I joined the team by interviewing the software’s users - people on Enigma’s data team. The following design features were deemed most essential given this feedback.
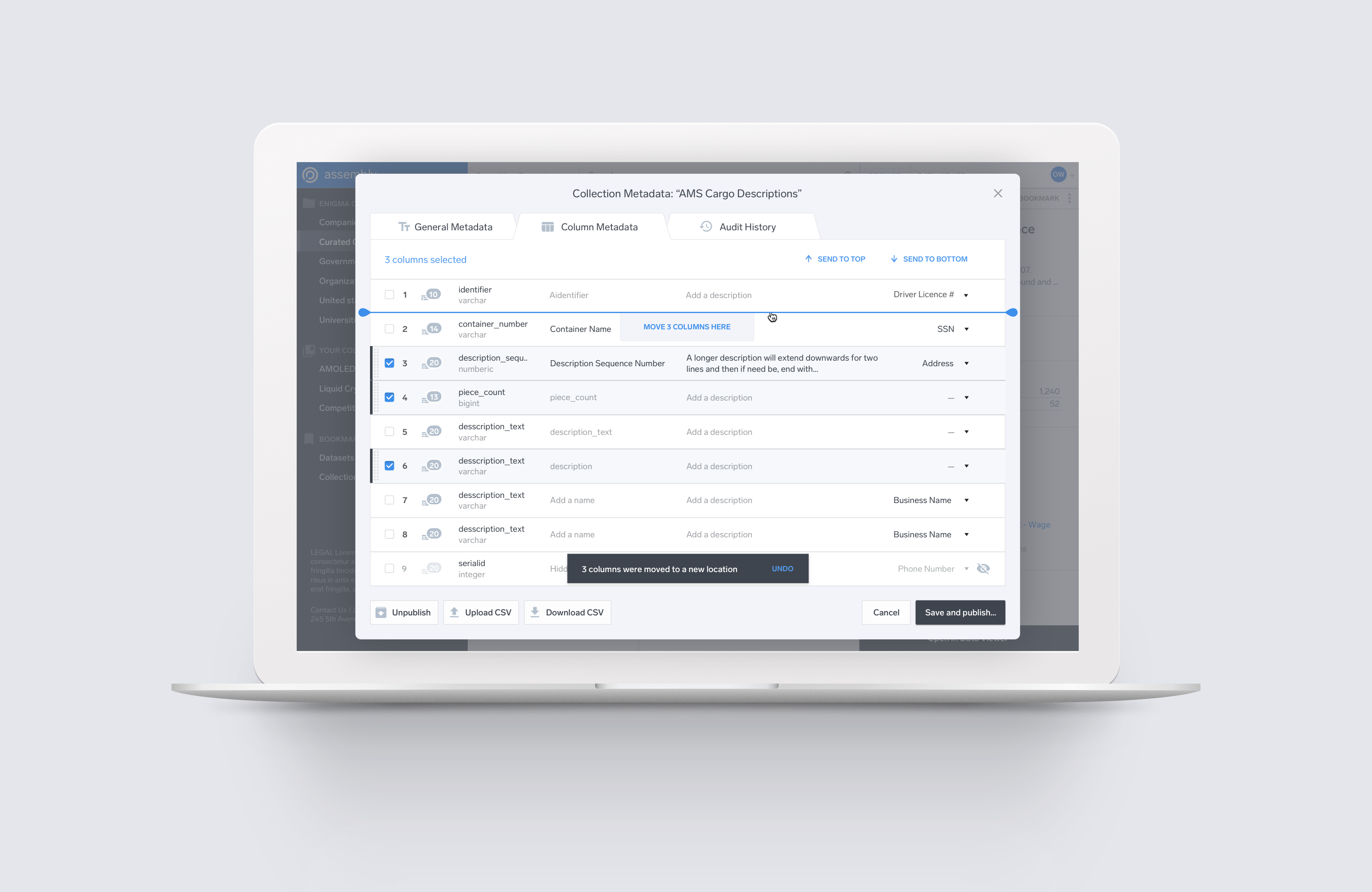
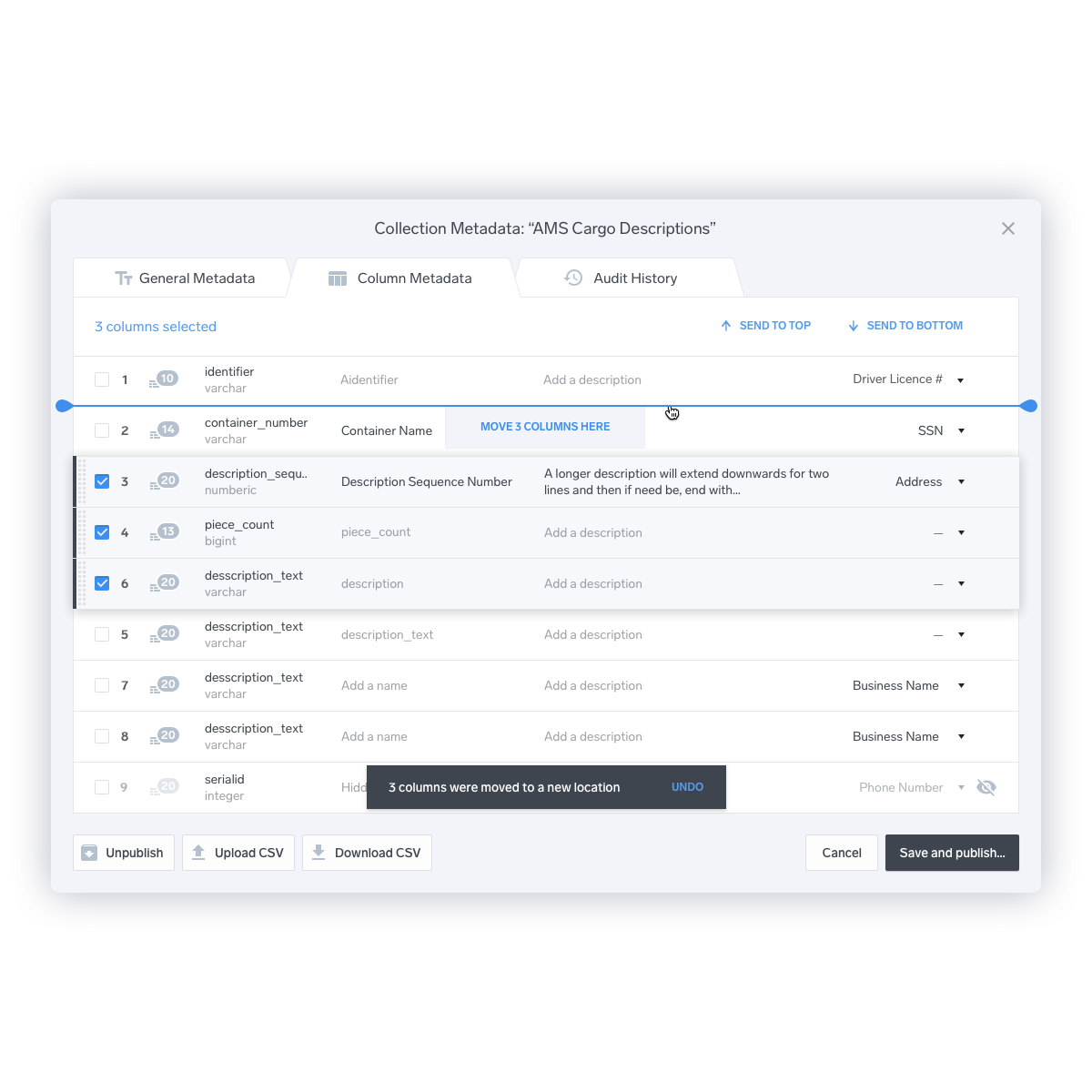
Reordering Multiple Columns at Once
This was one of the most consistently requested features. The old design forced the user to reorder columns one-at-a-time through a drag-and-drop interface. The redesigned version allows the selection of multiple columns at once, and allows the user to mouse over the desired place where they want to place the columns, in addition to dragging and dropping.
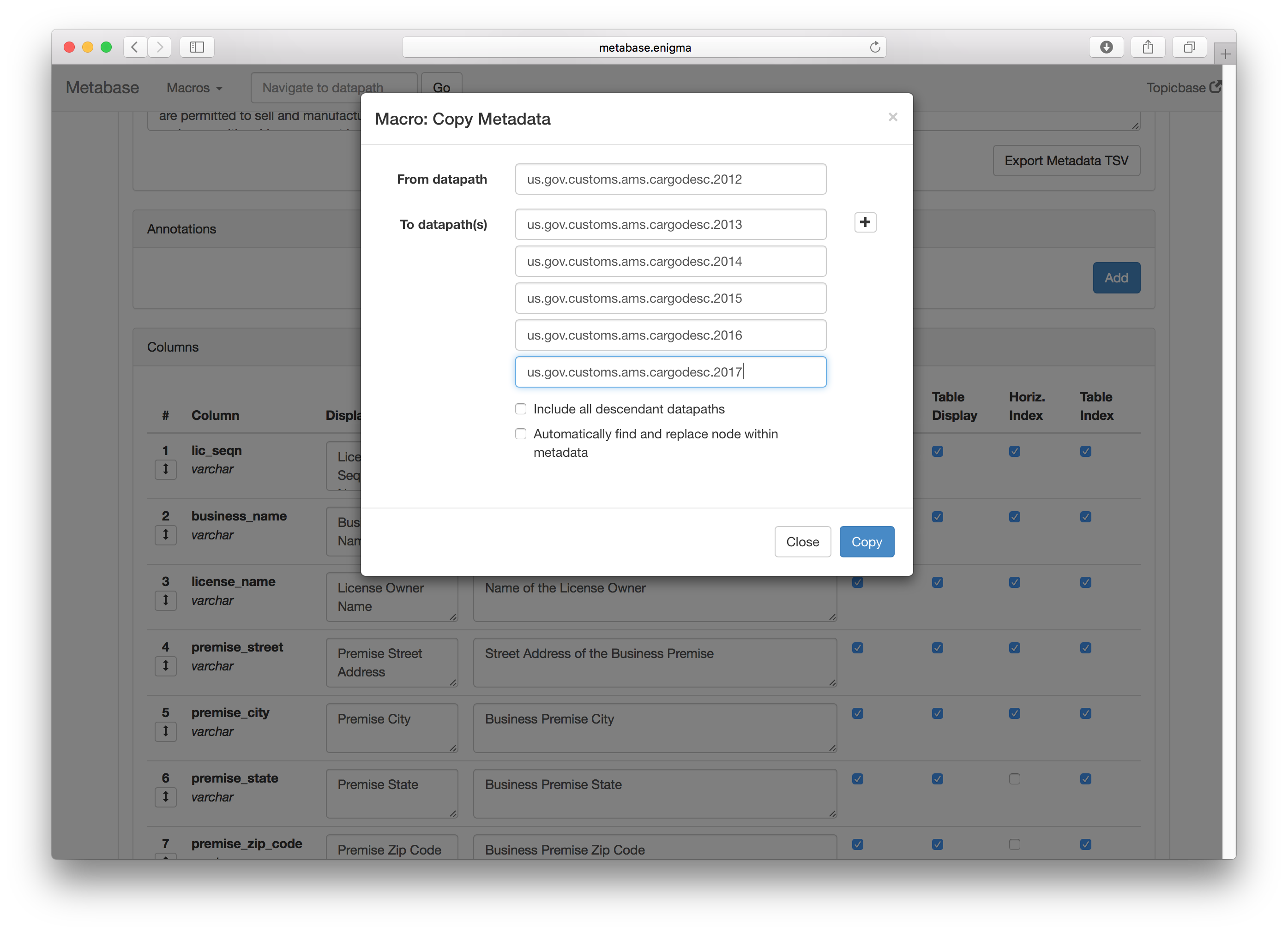
Applying Schema to Multiple Datasets
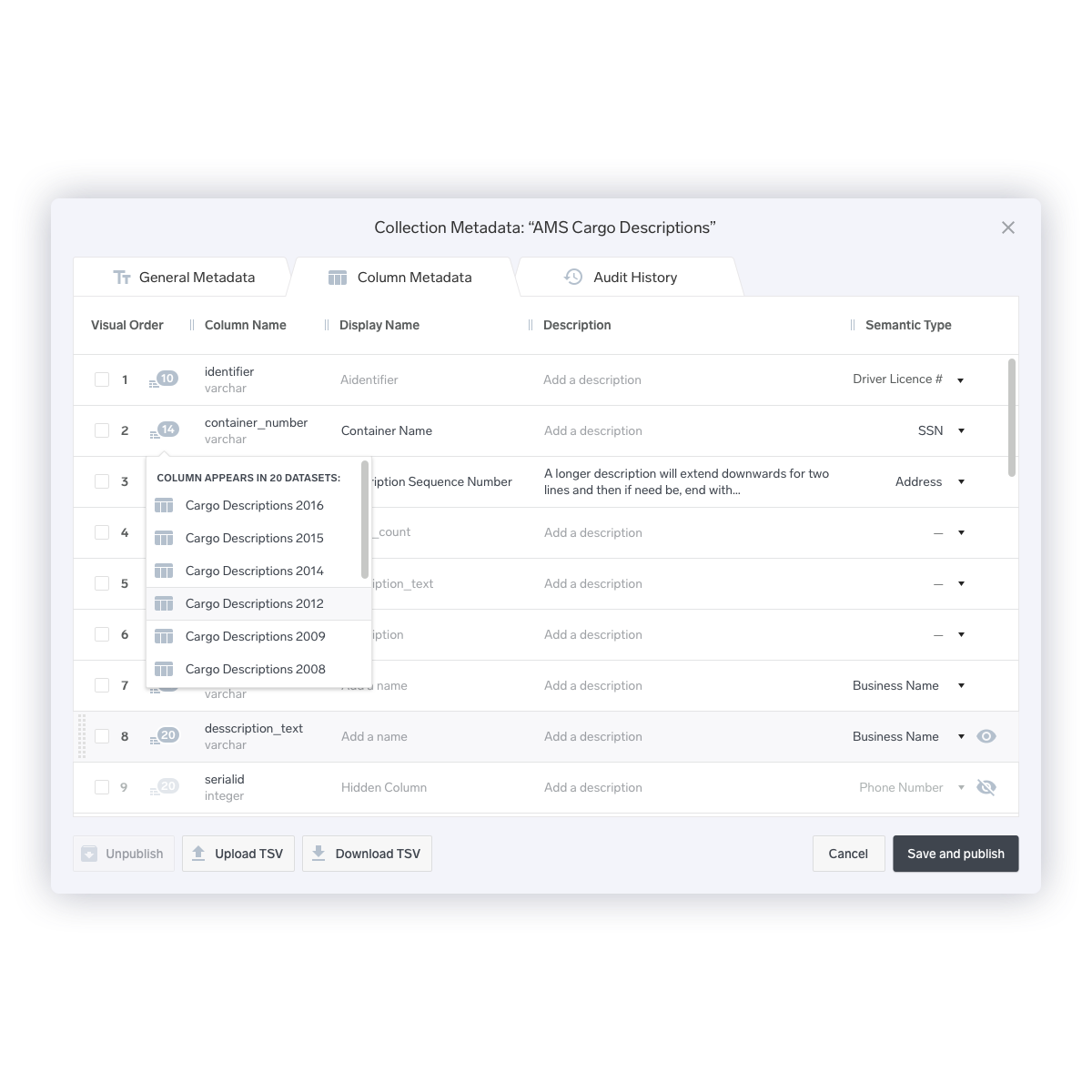
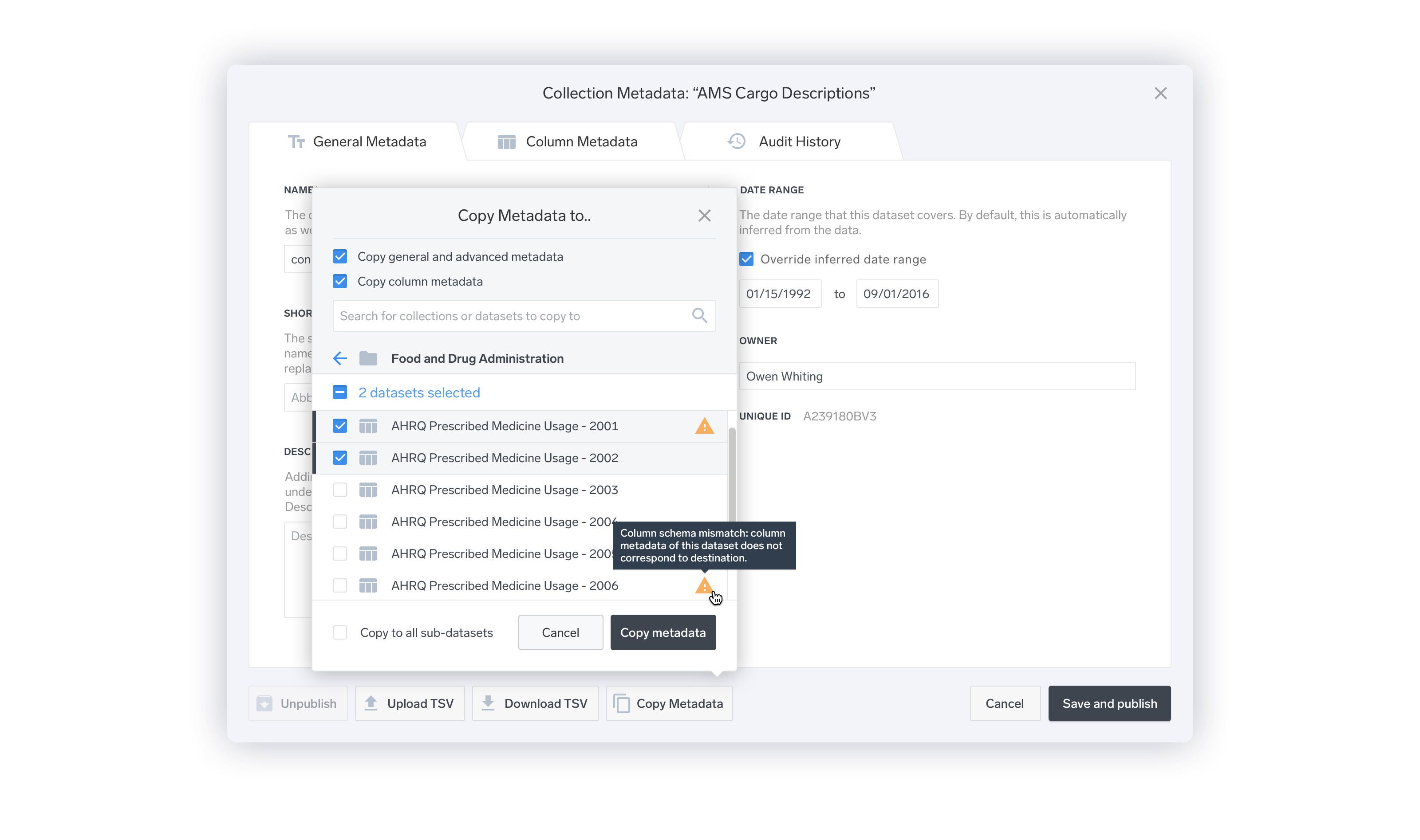
The existing design did account for the need to copy a dataset schema to another dataset. However, what was missing was the ability to copy a schema to a dataset that was slightly different- for example, a dataset that had one extra field.
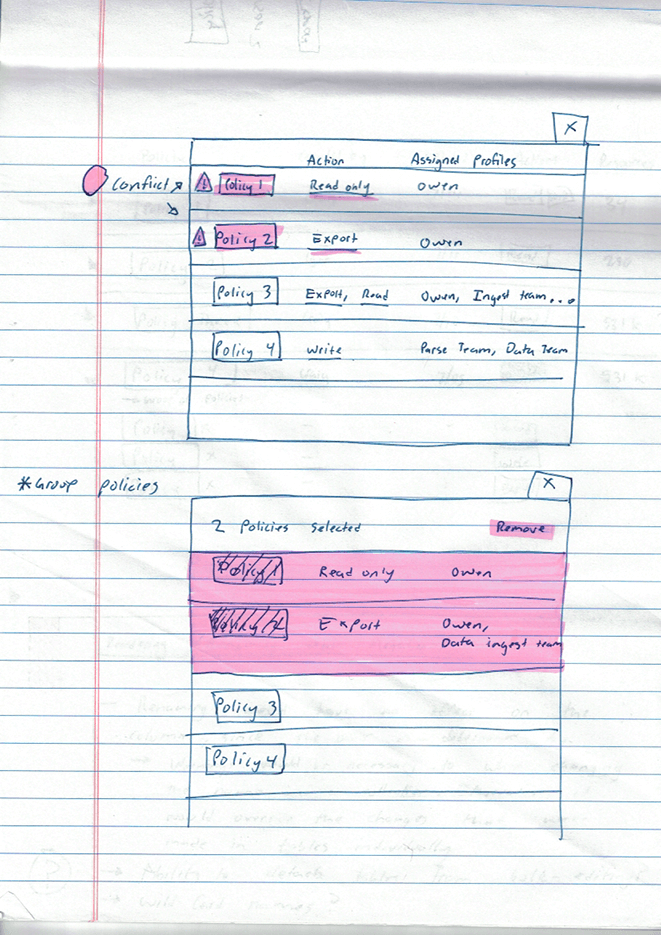
The new design allows the user to edit all of the metadata for all children datasets within a directory at once. If the a column is different within one of the datasets, an indicator alerts them to that.
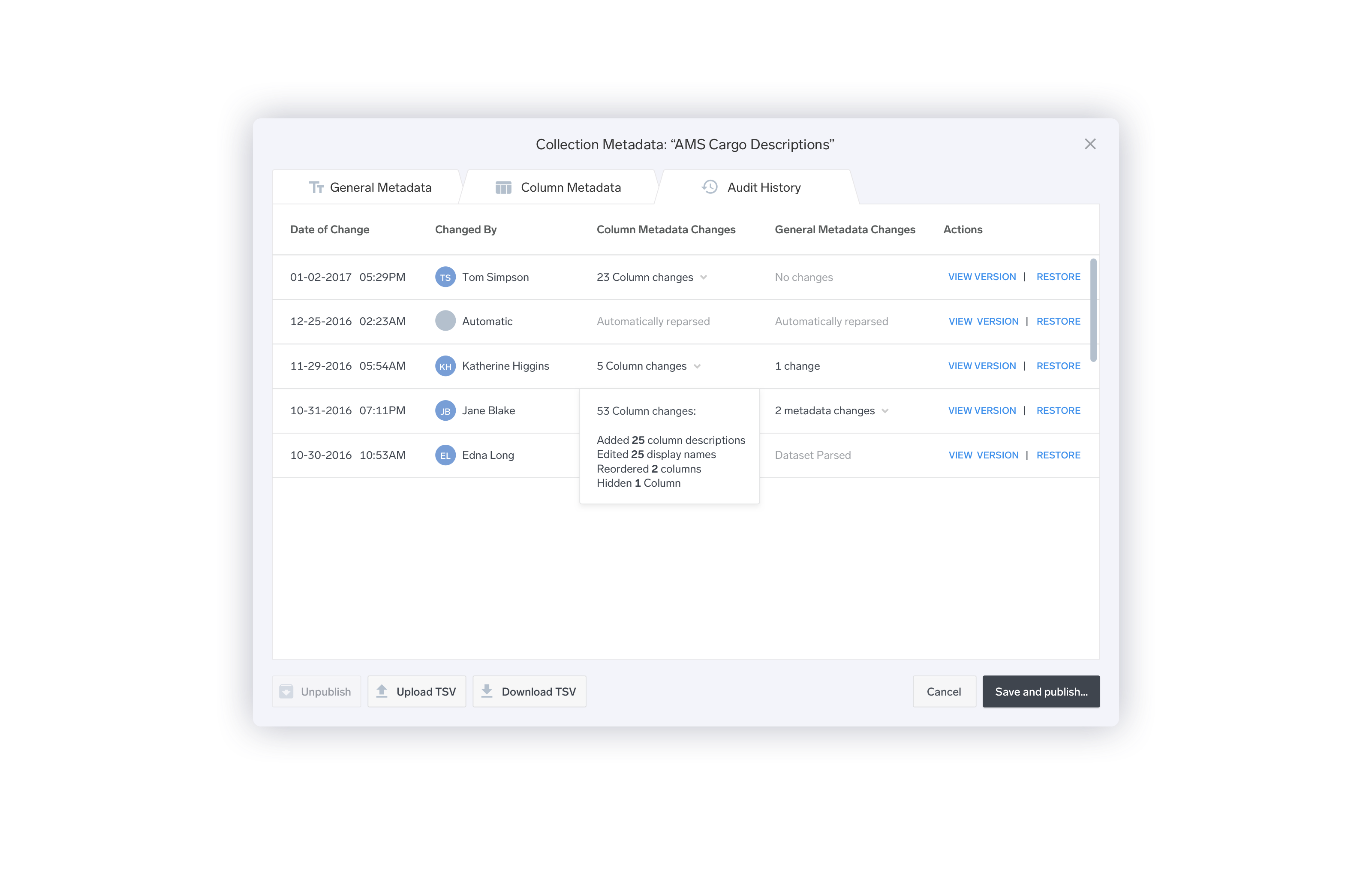
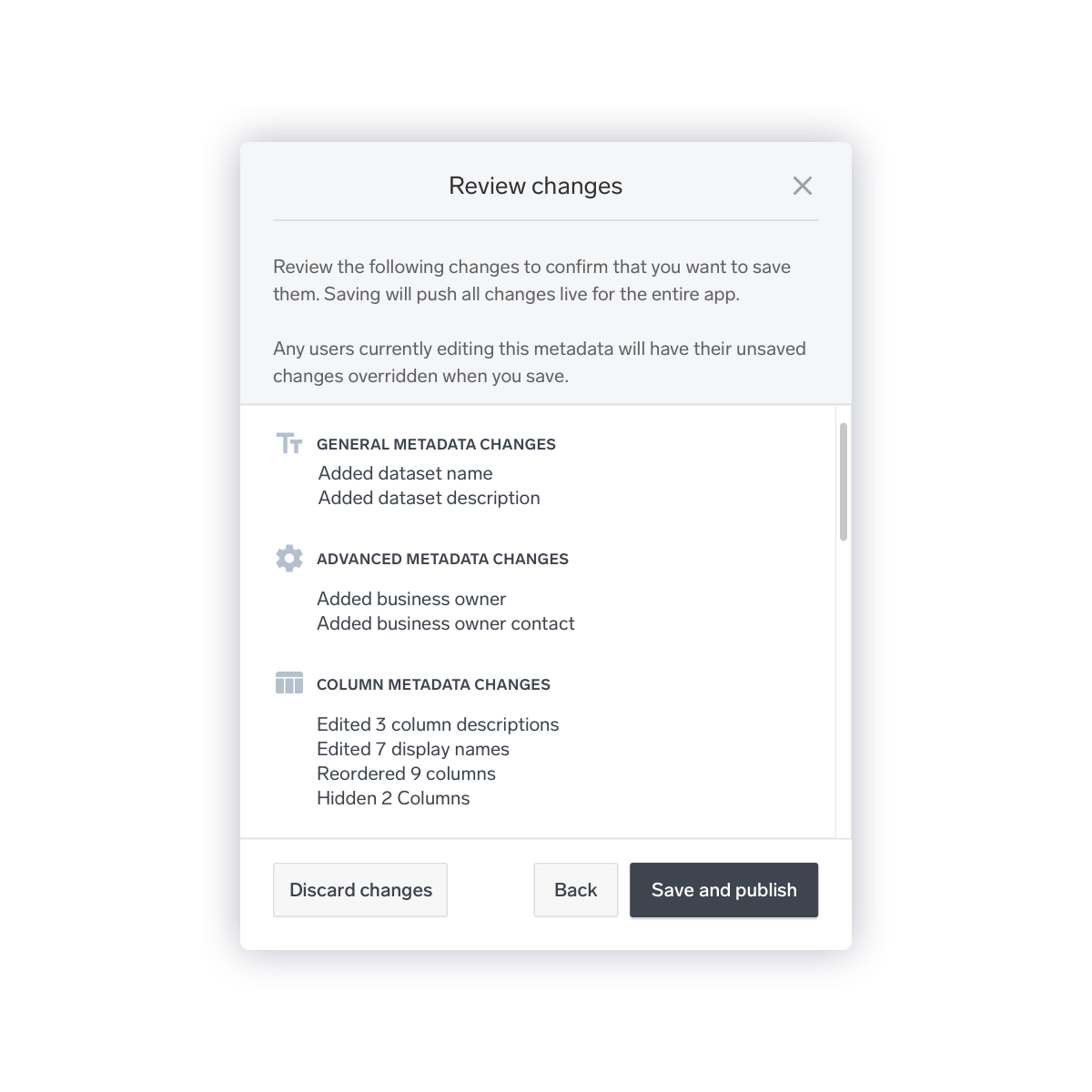
Explicit Confirmations when Changes Have Been Made.
Previously, the user could have little sense of what changes had been made. Furthermore, there was always the potential risk of two users simultaneously editing one dataset, and one user saving over potentially days of work that the other user had done.
I added a confirmation message detailing the changes that had been made to the dataset or directory, and asking the user to either confirm, discard, or continue editing.
The Approach
Design Process
I created the designs of the metadata editor during an early phase of the overall redesign of Enigma Public. Therefore, there were some significant changes to our thinking around how the metadata editor was going to function as I progressed with the design.
Originally, the old design was a completely separate tool from Public. It was accessible to any Enigma employee who logged into our secure network through our VPN, but it was built as a separate, disparate tool. My original task was simply to “redesign the existing product.” As such, my early designs mimicked this behavior.
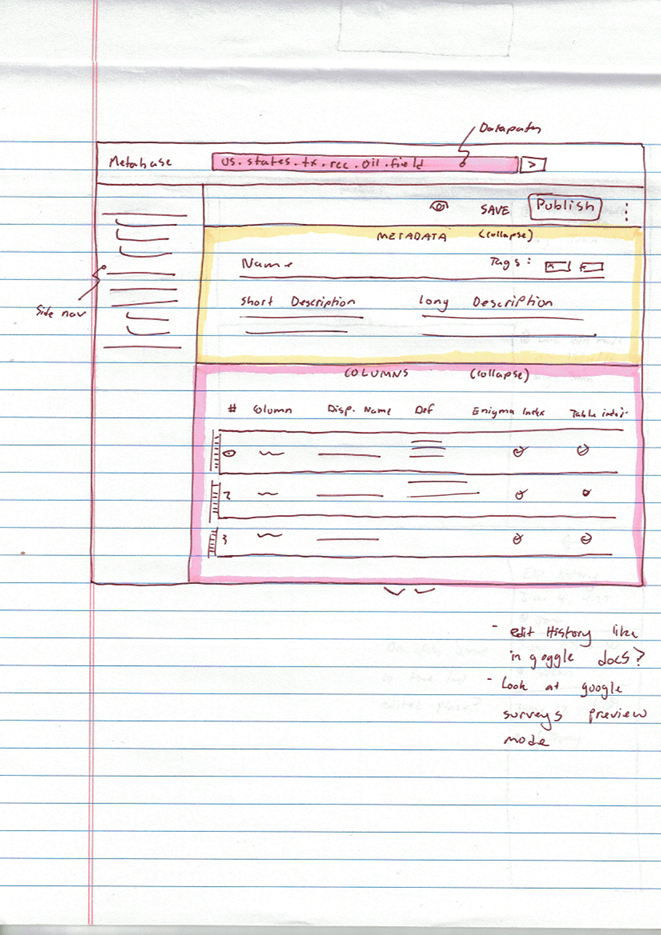
Wireframes
I began the wireframing process by creating rough hand-sketches. After I felt comfortable with the rough hand-sketches I made, I was able to begin prototyping in low-fidelity. At the time I created these wireframes, there was no visual system in place, so I followed our old brand guidelines.

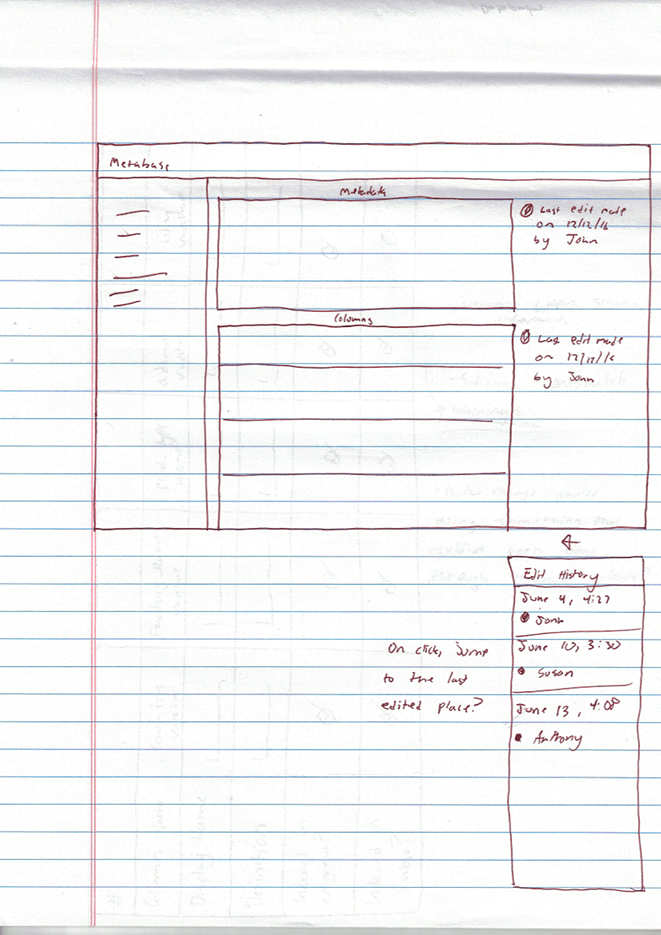


A Change in Our Thinking
The more thinking we did, however, the more advantages we saw to bringing the metadata editor in-line with the rest of Public. Why force the user to navigate to the same dataset twice, when it can just be accessed once from the front-end of public?
The Hand-Off
Build and Implementation
As the designs were handed off to our front-end team, some compromises had to be made. One major feature that I had included in the designs got left out: the feature for applying one set of metadata to multiple datasets at once with differing schemas. Because of the complexity with implementing this design, it was left out until after the launch of Public.
To address the missing functionality, I added a much simpler “upload/download CSV” option, which allowed for a lot of the same functionality to be included, albeit in a slightly less convenient way.
Post-Launch
Validation and Insights
After the first version went live, I was able to validate the design through further user testing and feedback. While the consensus was that the design was a big improvement over the old version, testing did reveal some areas that could be better. Discoverability of the ability to select and move multiple columns at once was poor, due to the lack of any visual indicator that this was possible. The original implementation lacked any confirmation message once the edits had been made, which left users hanging, unsure of whether their changes had been made. And finally, the interaction of reordering columns lacked an undo ability, which meant that the user was forced to delete all changes.
The Future of the Metadata Manager
At the time of writing this, I am working on the design for a visual ontology manager, which is a service to manage the entity types, attributes, and relationships within Enigma’s data. This service may come to entirely replace the initial metadata manager presented here, since it’s essentially managing metadata on a much larger scale.